
Let’s discover Googlebot, the site-scanning Google’s crawler

Put us to the test!
The name immediately makes one think of something nice, and indeed the corporate image also confirms this feeling: more than anything else, however, Googlebot is the fundamental spider software with which Google is able to scan the pages of public websites, following the links that start from one page and connect it to others on the Web, and thus selecting the resources that deserve to be included in the search engine’s Index. In short, this little robot is at the basis of Google’s entire crawling and indexing process, from which it derives its ranking system, and it is therefore not by chance that the search engine team has devoted more attention to the subject: let’s try to find out everything we need to know about Googlebot, the crawler that has the task of scanning the Web for sites and contents on behalf of Big G.
What Googlebot is
Today, let us therefore take a step back from the issues related to optimisation practices and try to briefly explain what Googlebot is and how it works, but above all why it is important for a site to know how Google looks at us – in a nutshell, because having a basic understanding of how search engine crawling and indexing works can help us to sense, prevent or solve technical SEO problems and ensure that the site’s pages are properly accessible to the crawlers themselves.
The latest in chronological order to delve into this topic comes from the update of Google’s official guide to Googlebot, but the crawler had already previously been the focus of an episode of SEO Mythbusting, the YouTube series by Martin Splitt who, prompted by the requests of many webmasters and developers and by the precise question of Suz Hinton (Cloud Developer Advocate at Microsoft, host of the occasion), went on to clarify some features of this software.
On this occasion, Splitt had provided a clear and simple definition of Googlebot, which is basically a programme that performs three functions: the first is crawling, the in-depth analysis of the Web in search of pages and contents; the second is indexing these resources, and the third is ‘ranking’, which, however, ‘no longer does Googlebot’, he further specified.
In practice, the bot takes content from the Internet, tries to understand the subject matter of the content and what ‘material’ can be offered to users searching for ‘these things’, and finally determines which of the previously indexed resources is actually the best for that specific query at that particular moment.
What Googlebot does and what it is for
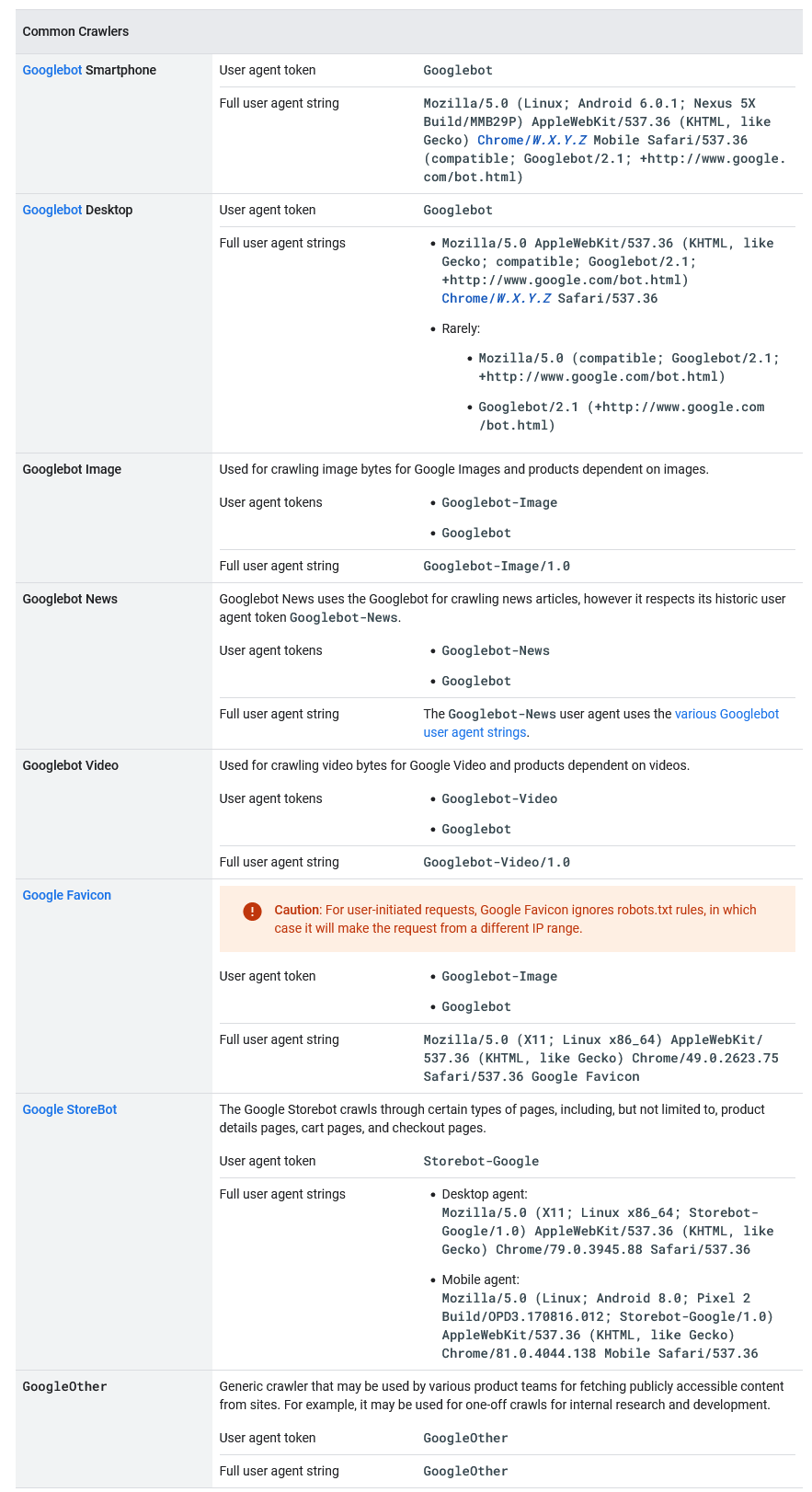
Wanting to go deeper, Googlebot is a special software, commonly referred to as a spider, crawler or simply bot, which scans the web by following the links it finds within pages to find and read new or updated content and suggest what should be added to the Index, the ever-expanding inventory library from which Google directly extracts online search results.
This software allows Google to compile over 1 million GB of information in a fraction of a second, and so behind its cute appearance – the official image of Googlebot depicts precisely a cute little robot with a lively, vaguely Wall-E-like look, ready to embark on a quest to find and index knowledge in all the as yet unknown corners of the Web – there is a powerful machine that scans the Web and adds pages to its index constantly.

More precisely, then, Googlebot is the generic name for two different types of crawler: a desktop crawler simulating a user using a desktop device, and a mobile crawler simulating a user using a mobile device. Sometimes our site is visited by both versions of Googlebot (and in this case we can identify the sub-type of Googlebot by examining the user agent string in the request), but if our site has already been converted to mobile-first on Google, most of Googlebot’s crawling requests are made using the mobile crawler, while a small part is made with the desktop crawler, and vice versa for sites that have not yet been converted (as Google explains in fact, the minority crawler only crawls URLs already crawled by the majority crawler).
Moreover, again from a technical point of view, both Googlebot desktop and Googlebot mobile however share the same product token (user agent token) in the robots.txt file, so we cannot selectively target Googlebot for smartphones or Googlebot for desktops using the robots.txt file.
Google’s other bots
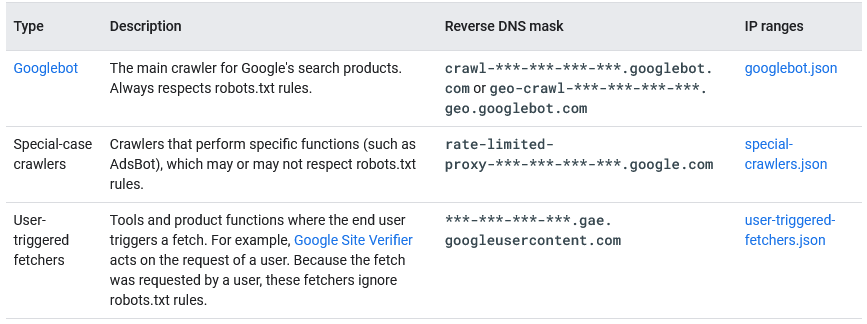
Google uses crawlers and fetchers (tools such as a browser that require a single URL when requested by a user) to perform actions for its products, either automatically or triggered at the user’s request. Googlebot is only Google’s main crawler, but it is not the only one, and indeed there are several robots, which have specific tasks and can be included in three broad categories, as the new version of Mountain View’s official document, updated at the end of April 2023, explains:
- Common crawlers, including precisely Googlebots, which are used to create Google search indexes, perform other product-specific scans, and for analytics. As a distinguishing feature, they always abide by the rules in the robots.txt file, have as their reverse DNS mask “crawl-***-***-***-***.googlebot.com or geo-crawl-***-***-***-***.geo. googlebot.com,” and the list of IP ranges can be found in the specific googlebot.json file.
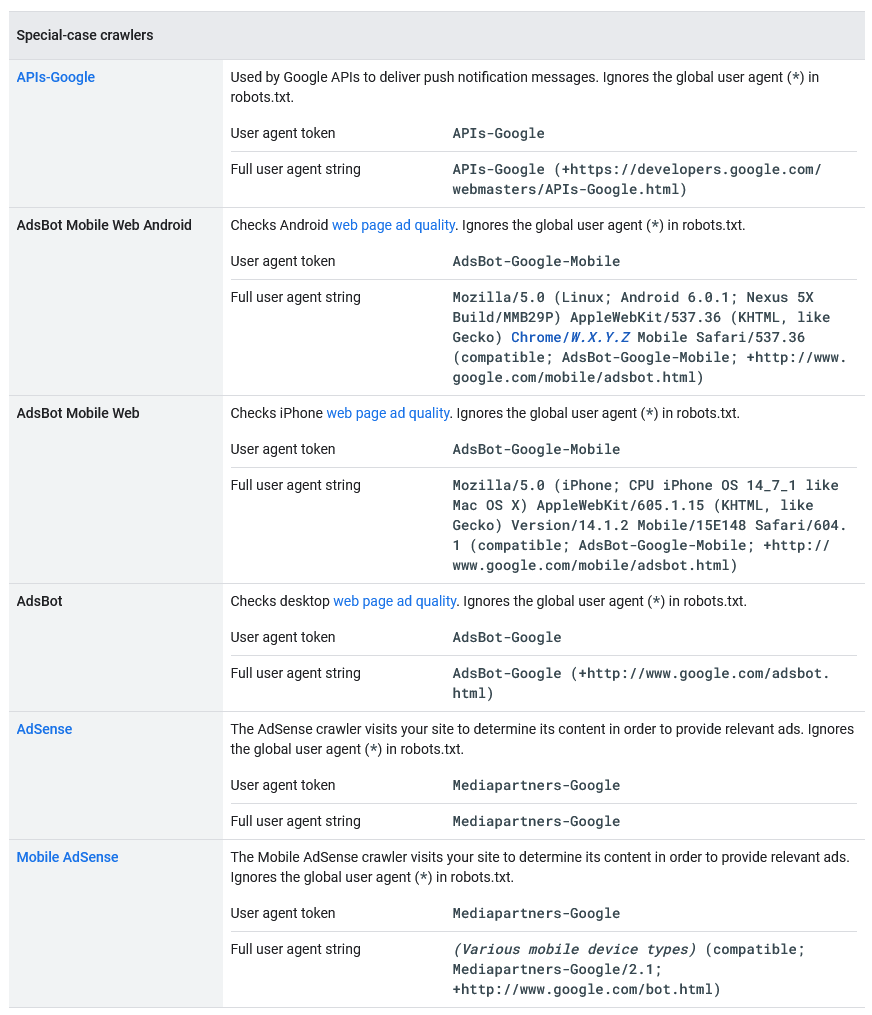
- Special crawlers: crawlers that perform specific functions, used by specific products where there is an agreement between the site being crawled and the product regarding the crawling process, and which may or may not comply with robots.txt rules. For example, AdSense and AdsBot control the quality of ads, while Mobile Apps Android controls Android apps, Googlebot-Image tracks images, Googlebot-Video videos, and Googlebot-News the news. Their reverse DNS mask is “rate-limited-proxy-***-***-***-***.google.com” and the list of IP ranges can be found in the special-crawlers.json file (and is different from those of common crawlers).
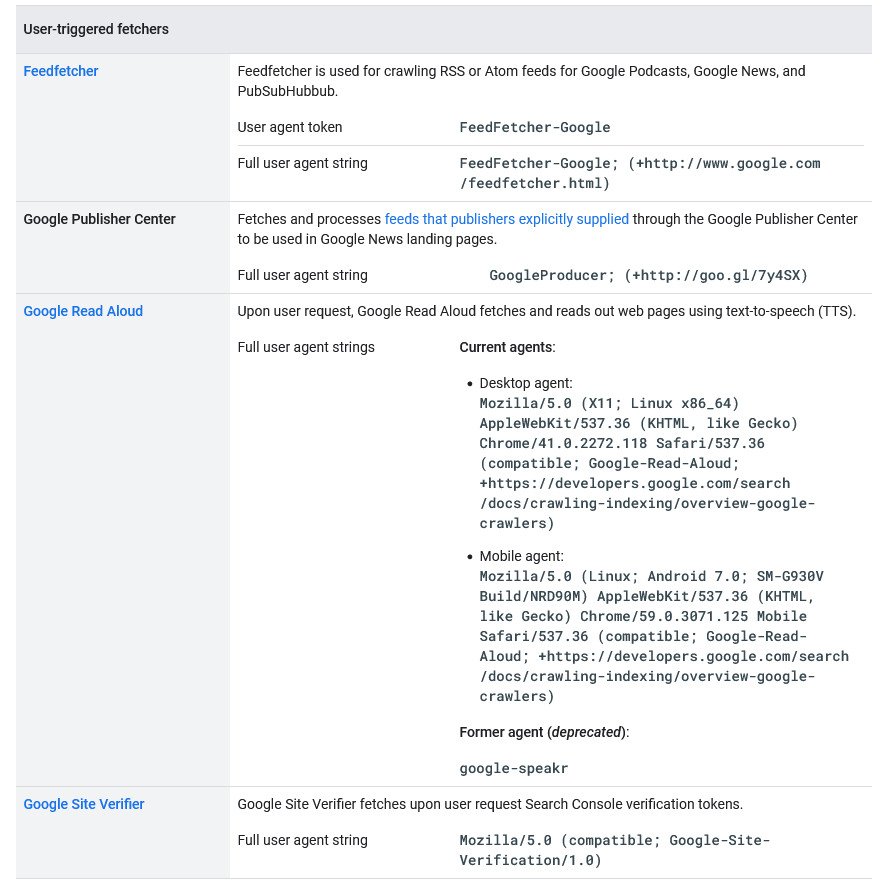
- User-triggered fetchers: tools and product functions where the end user triggers a fetch, such as Google Site Verifier acting on a user’s request. Because the fetch was requested by a user, these fetchers ignore robots.txt rules. Their reverse DNS mask is “***-***-***-***.gae.googleusercontent.com” and the list of IP ranges can be found in the user-triggered-fetchers.json file.
This official mirror helps us keep an eye on all possible (mostly desired) visitors to our site and pages, divided into the three categories just described.
Googlebot’s technical characteristics: an evergreen and super fast spider
As of May 2019, there was a fundamental technical innovation for Big G’s crawler: in order to ensure support for the newest features of web platforms, in fact, Googlebot became evergreen and continuously updated, equipped with an engine capable of constantly managing the latest version of Chromium when rendering web pages for Search.
According to Google, this function was the ‘number one request’ from participants in events and communities on social media with respect to implementations to be made to the bot, and so the Californian team focused on the possibility of making GoogleBot always up-to-date with the latest version of Chromium, carrying out work that lasted years to work on Chromium’s deep architecture, optimise layers, integrate and make rendering work for Search, and so on.
In concrete terms, since then Googlebot has become capable of supporting more than a thousand new features, such as in particular ES6 and new JavaScript functionalities, IntersectionObserver for lazy-loading, and the Web Components API v1. Google then invites webmasters and developers to check whether their site performs transpiling or uses polyfills specifically for GoogleBot, and if so, to assess whether it is still necessary in the light of the new engine, also pointing out that there are still some limitations, especially for JavaScript.
In particular, in these cases Google still needs to scan and render JavaScript in two stages: first GoogleBot scans the page, then it repeats the operation to render it graphically in full.
A necessary step to modernise the spider and bring benefits to developers and end users
Until May 2019, GoogleBot had been deliberately kept obsolete (to be precise, the engine was tested on Chrome v41, released in 2015) to ensure that it indexed web pages compatible with older versions of Chrome. However, in recent times an issue had become widespread for websites built on modern frameworks with features not supported by Chrome 41, which then suffered the opposite effect and encountered difficulties.
The decision to make GoogleBot and its search engine evergreen solves this problem and, at the same time, represents positive news for end users, who can now enjoy faster and more optimised experiences.
As Ilya Grigorik, Google’s web performance engineer, wrote on twitter, there will be no more ‘transpiling of ES6’ or ‘hundreds of web features that no longer require polyfilling or other complex workarounds’, which will also benefit the many sites that have sent the same transpiled code to everyone.
How the new Googlebot engine works
Already before the official confirmation, in fact, some international experts, and in particular Alec Bertram of DeepCrawl, had discovered that Google was testing a more modern version of GoogleBot with features present in Chrome v69 or later, instead of the traditional ones of Chrome v41. And Martin Splitt himself confirmed the test with a tweet, in which he said that tests are frequent at Google and are sometimes visible.
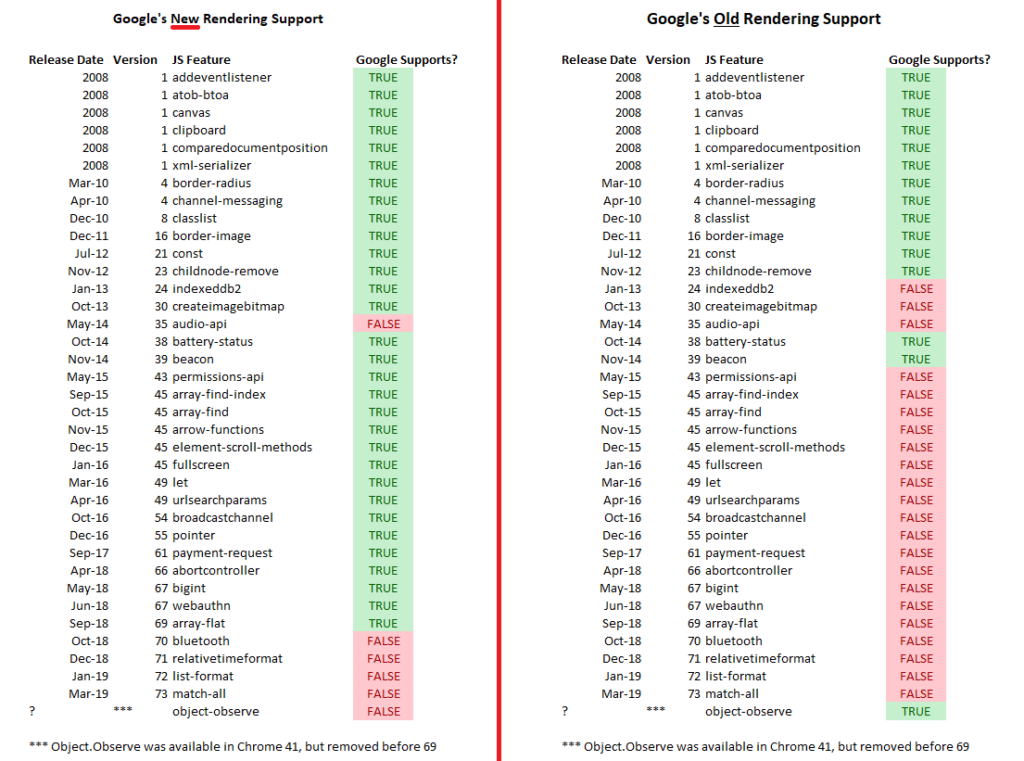
Specifically, the novelty concerns the support of certain JavaScript functions by GoogleBot, which in the new version has been greatly extended in comparison with previous versions: in the scripts launched by DeepCrawl and shown on the page, one can grasp the various differences between Chrome version 41 (which, as mentioned, was the basic one used at the time) and version 69 (one of the most current in May 2019).
Common issues with JavaScript
The article also explains some details of classic web crawling operations: search engines can fetch or download the HTML of a web page, extract its content and use it to index and rank pages. As web development has evolved, developers have started to use complex client-side JavaScript in the browser to make their pages faster, lighter and more dynamic.
These JavaScript features cause problems for the classic fetch activity of crawlers: while downloading JavaScript functions, they perform no other operations and thus cannot see any content added to the page with JavaScript.
For this reason, search engine crawlers and GoogleBot have adapted to these changes, implementing a rendering phase in crawling after the fetch phase, which essentially loads the crawled page into a browser, allows it to fully load and execute any JavaScript, and then uses the content found in the rendered page when indexing and positioning a URL.
What the GoogleBot update means for SEOs
The final GoogleBot update has brought important effects for SEOs and developers, especially from a practical point of view: the fact that Google is able to display web pages like a modern browser should give fewer worries about the interpretation of resources of various kinds, including modern web apps, limiting the use of alternative solutions such as dynamic rendering to render crawled content, indexing and ranking on Google.
Google rankings and Googlebot, what is the relationship?
Going back to Splitt’s video (and especially the mention of ranking), the developer advocate of the Google Search Relations team further explains the concept of Googlebot and ranking, specifying that the Google ranking activity is informed by Googlebot, but is not part of Googlebot.
This therefore means that during the indexing phase, the programme ensures that the crawled content is useful for the search engine and its ranking algorithm, which uses, as we have said several times, specific criteria to rank pages, the famous 200 ranking factors.
An example to understand the relationship: Search as a library
Therefore, the aforementioned similarity with a library, where the manager “has to determine what the contents of the various books are in order to give the right answers to the people who ask to borrow them, comes in handy. To do this, he consults the catalogue of all the volumes present and reads the index of the individual books’.
The catalogue is thus the Google Index created through Googlebot’s scans, and then ‘someone else’ uses this information to make considered decisions and present users with the content they require (the book they want to read, to continue the analogy given).
When a person asks the librarian ‘what is the best book to learn how to make apple pies very quickly’, the librarian must be able to answer appropriately by studying the subject indexes of the various books that talk about cooking, but also know which ones are the most popular. So, in the Web sphere we have the index provided by Googlebot and the ‘second part’, the classification, which is based on a sophisticated system that studies the interaction between contents present in order to decide which ‘books’ to recommend to those who ask for information.
A simple, non-technical explanation of scanning
Splitt later returned to clarify the analogy on how Googlebot works, and an article in SearchEngineLand quotes his words to explain in a non-technical way the crawling process of Google’s crawler.
“You’re writing a new book and the librarian has to actually take the book, figure out what it’s about and also what it relates to, whether there are other books that might have been source or might be referenced by this book,” the Googler said. In his example, the librarian is Google’s web crawler, i.e. Googlebot, while the book is a website or web page.
Simplifying, the indexing process then works like this: ‘You have to read [the book], you have to understand what it is about, you have to understand how it relates to other books, and then you can order it in the catalogue’. Thus, the content of the web page is stored in the ‘catalogue’, which out of metaphor represents the index of the search engine, from where it can be sorted and published as a result for relevant queries.
In technical terms, this means that Google has ‘a list of URLs and we take each of these URLs, make a network request to them, then look at the server’s response and then render it (basically, we open it in a browser to run JavaScript); we then look at the content again and then put it in the index where it belongs, similar to what the librarian does’.
When does Googlebot scan a site?
Having completed the theoretical discussion, the video then discusses more technical issues related to the Mountain View bot, and in particular Splitt explains how and when a site is crawled by Googlebot: ‘In the first crawling phase we arrive at your page because we found a link on another site or because you submitted a sitemap or because you were somehow entered into our system. One such example is using the Search Console to report the site to Google, a method that gives the bot a hint and a trigger.
How often Googlebot crawls
Linked to this issue is another important point, the frequency of crawling: Splitt starts by saying that the bot tries to understand whether among the resources already in the Index there is something that needs to be checked more often. That is, is the site offering news that changes every day, is it an eCommerce site offering offers that change every 15 days, or even does it have content that does not change because it is a museum site that is rarely updated (perhaps for temporary exhibitions)?
What Googlebot does is to separate the index data into a section called ‘daily or fresh’ which is initially crawled assiduously and then reduced in frequency over time. If Google notices that the site is ‘super spammy or super broken’, Googlebot may not scan the site, just as the rules imposed on the site keep the bot away.
How Google’s scanning works
The video also adds that Googlebot does not simply scan all the pages of a site at the same time, both due to internal resource limitations and to avoid overloading the site’s service.
So, Google tries to figure out how far it can go in crawling, how much of its own resources it has at its disposal, and how much it can stress the site, determining what is often referred to as the crawl budget and which is often difficult to determine. “What we do,” adds Splitt, “is launch a crawl for a while, raise the intensity level and when we start to see errors reduce the load.
Is my site visited by Googlebot?
This is the crawler part of the Google spider, which is followed by other more specific technical activities such as rendering; for sites, however, it can be important to know how to tell if a site is being visited by Googlebot, and Martin Splitt explains how to do this.
Google uses a two-stage browser (crawling and true rendering), and at both times it presents sites with a request with a user agent header, which leaves clearly visible traces in the referrer logs. As we read in Mountain View’s official documents, Google uses about ten user-agent tokens, which are responsible for a specific part of crawling (e.g. AdsBot-Google-Mobile checks the ad quality on the Android web page).
Sites may choose to offer crawlers a non-full version of pages, but a pre-rendered HTML specifically to facilitate crawling: this is what is called dynamic rendering, which means in practice having client-side displayed content and pre-visualised content for specific user-agents, as stated in Google’s guides. Dynamic rendering or dynamic rendering is especially recommended for sites that have JavaScript-generated content, which remains difficult for many crawlers to process, and provides user-agents with content suited to their capabilities, such as a static HTML version of the page.
The episode of SEO Mythbusting goes on to pay attention to a hot topic, namely mobile browsing; specifically, Suz Hinton asks for details about the way Google analyses and distinguishes mobile and desktop site content. The Big G analyst first pauses to explain what mobile first index is for Google, i.e. the way in which ‘we discover your content using a mobile user agent and a mobile viewport’, which serves the search engine to make sure to offer something nice to people browsing from a mobile device.

Continuing his discourse, Martin Splitt also devotes attention to the related concepts of mobile readiness or mobile friendliness: making a page mobile friendly means making sure that all content fits in the viewport area, that the ‘tap targets’ are wide enough to avoid pressure errors, that the content can be read without necessarily having to enlarge the screen, and so on.
All this is an indicator of quality for Google, i.e. one of the 200 ranking factors we mentioned earlier, although in the end the advice the analyst gives is to ‘offer good content for the user‘, because that is the most important thing for a site.
The official guide to Googlebot: how to access and block the site
We have mentioned that in the past few days, there has been an update of Google’s official documentation dedicated to Mountain View, in particular for the section explaining how the crawler works and how to access a site.
First of all, the guide points out that Googlebot should not access most sites on average more than once every few seconds, but that, due to possible delays, this frequency might be slightly higher in short periods.
Googlebot was designed to be run simultaneously by thousands of machines to improve performance and keep up with the pace of growth of the Web. In addition, to reduce bandwidth utilisation Google runs many crawlers on computers close to the sites they might scan. Therefore, our log files might indicate visits to google.com from different computers, all with the Googlebot user agent: however, Google’s goal is to scan as many pages of the site as possible on each visit without overloading the server’s bandwidth, and if the site cannot keep up with Google’s scanning requests, we may request to change the scanning frequency.
Typically, Googlebot scans on HTTP/1.1. However, from November 2020, Googlebot may scan sites that could benefit on HTTP/2, if supported. This saves computing resources (e.g. CPU, RAM) for the site and Googlebot, but does not affect the indexation or ranking of the site.
To disable scanning over HTTP/2, we must instruct the server hosting the site to respond with an HTTP 421 status code when Googlebot attempts to scan the site over HTTP/2; if this is not feasible, we can use a temporary solution and send a message to the Googlebot team.
Googlebot can scan the first 15 MB of content in a supported HTML or text file. After this threshold, Googlebot stops scanning and only considers the first 15 MB of content for indexing anyway. More precisely, the 15 MB limit applies to retrievals performed by Googlebot (Googlebot Smartphone and Googlebot Desktop) when fetching file types supported by Google Search; the next content is deleted by Googlebot and only the first 15 MB is forwarded for indexing.
This limitation, however, does not apply to resources such as images or videos, because in this case Googlebot retrieves videos and images referenced in the HTML with a URL (e.g. <img src=”https://example.com/images/puppy.jpg” alt=”cute puppy looking very disappointed” />) separately with consecutive retrievals.
Google and 15 MB: what the limit means
It was precisely this reference to 15 MB, which appeared as mentioned at the end of June 2022, that triggered the reaction of the international SEO community, forcing Gary Illyes to write a further blog entry to clarify the matter.
First of all, the threshold of the first 15 megabytes (MB) that Googlebot ‘sees’ when retrieving certain file types is not new, but ‘has been around for many years’ and was added to the documentation ‘because it might be useful for some people when debugging and because it rarely changes’.
This limitation only applies to bytes (content) received for the initial request made by Googlebot, not to reference resources within the page. This means, for example, that if we open https://example.com/puppies.html, our browser will initially download the bytes of the HTML file and, based on those bytes, may make further requests for external JavaScript, images or anything else referenced by a URL in the HTML; Googlebot does the same thing.
For most sites, the 15 MB limit means ‘most likely nothing’ because there are very few pages on the Internet larger than that and ‘you, dear reader, are unlikely to own them, since the average size of an HTML file is about 500 times smaller: 30 kilobytes (kB)’. However, says Gary, “if you are the owner of an HTML page that exceeds 15 MB, perhaps you could at least move some inline scripts and CSS dust to external files, please”.
Data URLs also contribute to the size of the HTML file “because they are in the HTML file”.
To look up the size of a page and thus understand whether we exceed the limit there are several ways, but “the simplest is probably to use the browser and its developer tools”.
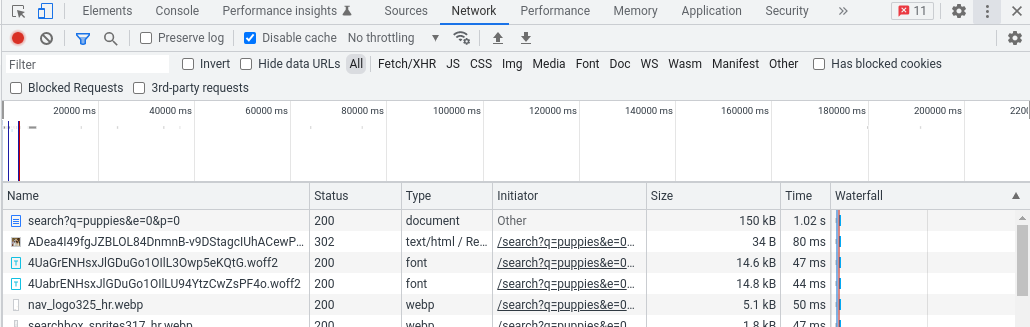
Specifically, Illyes advises, we need to load the page as we normally would, then start the Developer Tools and go to the Network tab; reloading the page we should see all the requests the browser had to make to render the page. The main request is the one we are looking for, with the size in bytes of the page in the Size column.
In this example from Chrome’s Developer Tools the page weighs 150 kB, which is shown in the size column:
A possible alternative for the more adventurous is to use cURL from a command line, as shown below:
curl
-A "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36"
-so /dev/null https://example.com/puppies.html -w '%{size_download}'How to prevent Googlebot from visiting the site
In some cases we might be tempted by the idea of preventing Googlebot from visiting the site.
However, says Google, ‘it is almost impossible to keep a web server secret by not publishing links to it’: for instance, as soon as a user follows a link from this ‘secret’ server to another web server, the ‘secret’ URL could be displayed in the referrer tag and be stored and published by the other web server in its referrer log. Similarly, many obsolete and inaccessible links exist on the Web. When someone publishes a bad link back to your site or does not update the links to reflect changes in your server, Googlebot tries to scan for a bad link on the site.
Ultimately, there are still a number of options to prevent Googlebot from crawling your site content – here for example are three ways to hide a site from Google, but not from users – but Google urges you to remember ‘the difference between preventing Googlebot from crawling a page, preventing Googlebot from indexing a page, and preventing it from crawlers and users altogether‘.
Google verification: the official IP list and reverse DNS look-up
Before blocking Googlebot, however, there is another aspect that should not be overlooked: the user agent string used by Googlebot is often spoofed by other crawlers, so it is very important to verify that a problematic request actually comes from Google.
The best way to verify that a request actually comes from Googlebot is to use a reverse DNS look-up in the request’s source IP, or to match the source IP with Googlebot’s IP address ranges, which Google decided to make public in November 2021 in response to community requests.
