
Here comes Google MUM, AI search algorithm a thousand times stronger than BERT

A thousand times more powerful than Google BERT: a remarkable presentation (and a promise) for Google MUM, the new search algorithm used by Search that, as Pandu Nayak explains, represents “a new milestone of Artificial Intelligence” for the understanding of information. This is one of the most interesting ads coming from Google I/O 2021, the global conference on Google ecosystem products, which is back in virtual form after a year of absence due to the pandemic.
What is Google MUM
It is called Multitask Unified Model, abbreviated to MUM, and is the new technology developed by Google to meet the most complex needs of search engine users, thanks to a greater and better understanding of the language that allows to provide more precise and useful answers to queries.
According to the words of the Google Fellow and Vice President of Search during the new and expected edition of Google I/O, MUM “is built on a Transformer architecture, just like BERT, but is 1,000 times more powerful”. Nayak emphasizes what are the innovative features of this artificial intelligence technology, which can help reduce the steps to get answers to complex queries made on the search engine.
“MUM not only understands language, but generates it“, he says. “It is trained to understand 75 different languages and performs many different activities at the same time, allowing him to develop a more complete understanding of information and knowledge of the world than previous models”. In addition, “MUM is multimodal, so it includes information through text and images and, in the future, can expand to multiple modes such as video and audio”.
Characteristics of Google MUM
The Multitask Unified Model is then both multitasking and multimodal: this means that it can connect information for users in new ways, and also understand information from different formats such as web pages, images and other simultaneously.
It represents an extraordinary evolution of BERT – which just less than two years ago was presented as “the biggest breakthrough in the last five years and one of the biggest leaps forward in the history of Research” – since it contains “a thousand times its number of nodes, or decision points in a neural network whose project is based on nerve junctions in the human brain” and is “trained using data scanned from the open web, removing low quality content” (Hdblog).
Language can be a significant obstacle to access to information. MUM has the potential to break down these boundaries by transferring knowledge through languages, because it can learn from sources that are not written in the language in which we wrote the research and help to get this information.
What is Google MUM for
Google MUM is useful to solve a common challenge for search engine users: “having to type many queries and perform many searches to get the answer you need”.
As Prabhakar Raghavan, Senior Vice President, points out, Google’s mission is to “make information more accessible and useful for all”, and AI progress “pushes the boundaries of what Google products can do”. Over the past two decades and more, the goal has been “develop not only a better understanding of information on the Web, but a better understanding of the world, because when we understand information, we can make it more useful, that you are a remote student learning a new complex subject, a caregiver looking for reliable information on COVID vaccines or a parent looking for the best route to get home”.
One of the hardest problems for search engines today is helping with complex tasks, “how to plan what to do during a family trip”: typically, these queries require more searches to get the information you need and, explains Raghavan, “on average people take eight searches to complete complex tasks“.
Another great advantage of this technology is the ability to remove language barriers: MUM may be able to transfer knowledge from sources in all languages and use this information to find the most relevant results in our preferred language.
Examples of functioning of the new algorithm
Nayak and Raghavan explain the operation of MUM through the same example: a hiking enthusiast has just finished the walk on Mount Adams (in the State of Washington), he is going on a hike to Mount Fuji in Japan the following fall and wants to know what to do differently to prepare.
Today “Google may be able to help you with this, but it would take a lot of thoughtful searches: you should look for the height of each mountain, the average temperature in the fall, the difficulty of the hiking trails, the right equipment to use, and more. After a series of searches, eventually you will be able to get the answer you need,” they say.
However, speaking to a (human) hiking expert, you could ask one direct question – “What should I do differently to prepare?” – and get a “weighted response that takes into account the nuances of your task and guides you through the many things to consider”.
Today’s search engines are not sophisticated enough to respond as an expert would, but with the new Multitask Unified Model technology “we are getting close to helping you with these kinds of complex needs” thus reducing the number of searches needed to do things.

Going back to the example of hiking on Mount Fuji, MUM could understand that we are comparing two mountains, so the information about the altitude and the trail could be relevant. You might also understand that in the context of hiking, “preparation” might include things like fitness training as well as finding the right equipment.
And so, by bringing out insights based on “his deep knowledge of the world”, MUM could point out that “although the mountains are about the same height, autumn is the rainy season on Mount Fuji, so you may need a waterproof jacket”. In addition, it could also bring out “useful secondary topics for deeper exploration, such as the most appreciated equipment or the best training exercises, with references to useful articles, videos and images from around the Web”.
Also very important is the ability to learn from different languages: for example, there may be “really useful information about Mount Fuji written in Japanese”, but “today, you probably won’t find them if you do not search for it in Japanese“. But MUM “could transfer knowledge from sources in all languages and use this information to find the most relevant results in your preferred language”, and “when you’re looking for information on visiting Mount Fuji, you might see results like where to enjoy the best mountain views, onsen (SPAs) in the area and famous souvenir shops, or all the information that is most commonly found during research in Japanese”.
A further futuristic application is the possibility to take a photo of the trekking boots and ask: “Can I use them for a hike on Mount Fuji?”. MUM could understand the image and connect it to the question, answering that those boots are suitable or referring to a blog with a list of recommended tools.
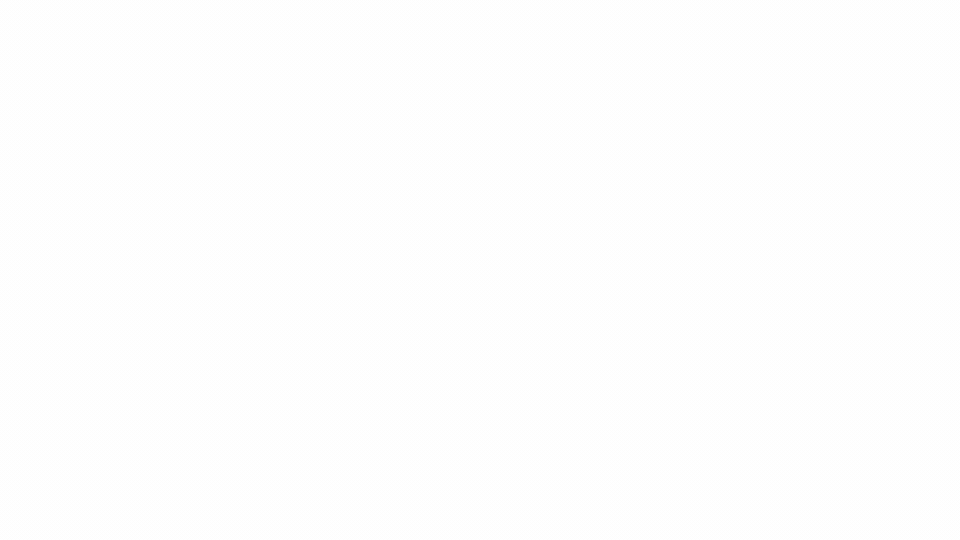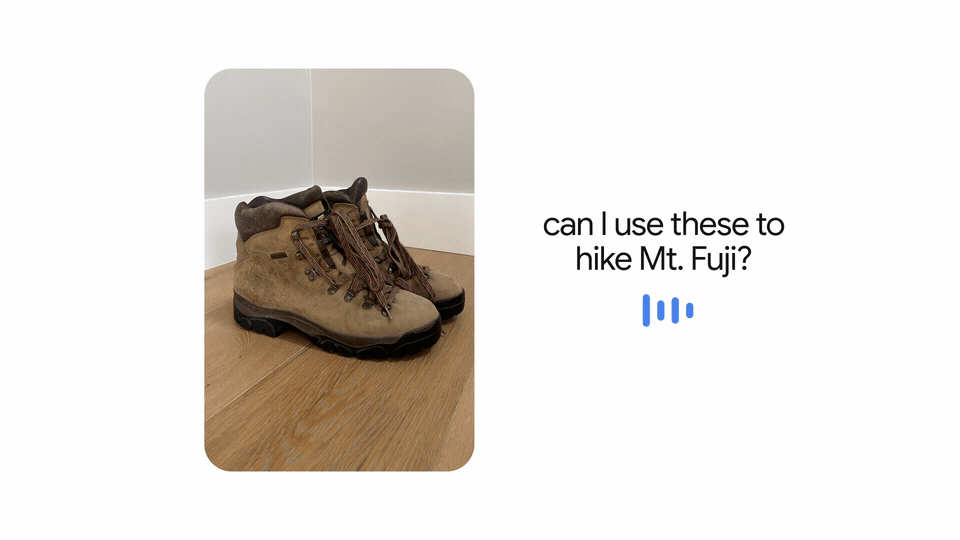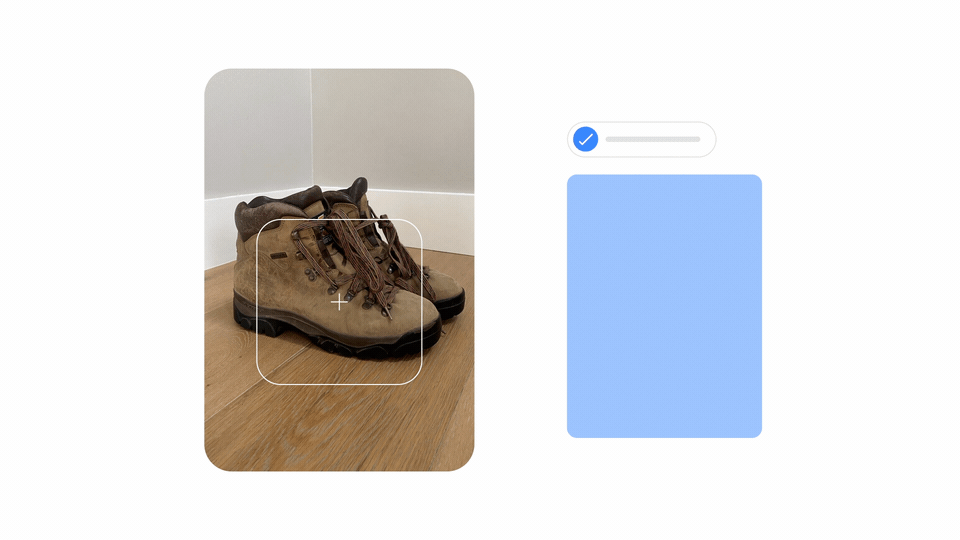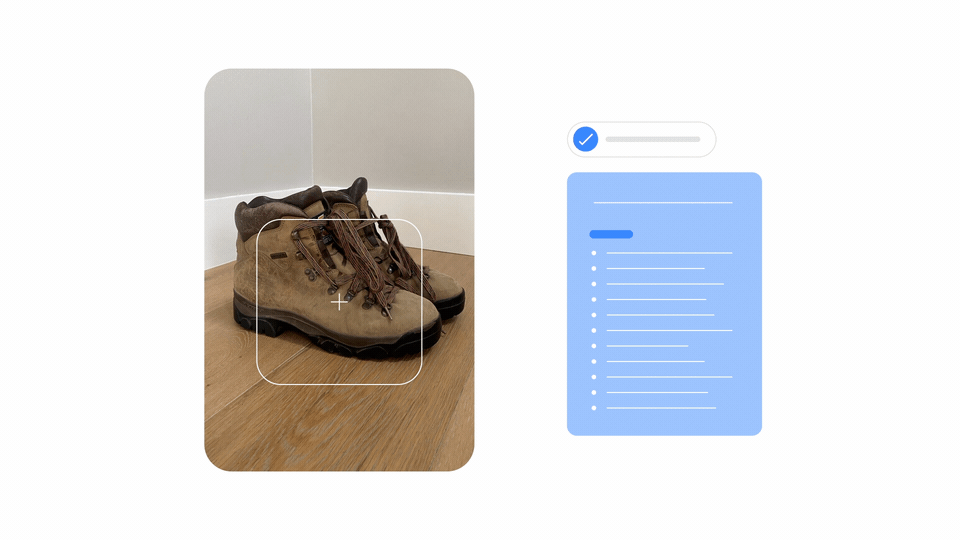
When Google MUM is going to debut in Search
But when will this revolution in research actually come? At the moment there are no hypotheses about the official launch of MUM on Google, because at the moment the company is engaged in the testing phase on this technology.
Nayak explains it clearly: “Every time we take a leap forward with artificial intelligence to make world information more accessible, we do it responsibly”. For this reason, “every improvement in Google Search is subjected to a rigorous evaluation process to ensure that we are providing more relevant and useful results”, also thanks to the support of human quality raters, which follow the Guidelines for Research Quality Evaluators and “help to understand how much our results help people to find information”.
In concrete, “just as we have carefully tested the numerous BERT applications launched since 2019, MUM will undergo the same process in which we apply these models in research”. In particular, it anticipates the Google Fellow and Vice President of Search, “we will look for patterns that could point to bias in machine learning, to avoid introducing bias into our systems”, and then “we will also apply the lessons learned from our latest research on how to reduce the carbon footprint of training systems such as MUM, to ensure that Search continues to function as efficiently as possible”.
And so, wanting to make a time forecast, “in the coming months and years we will bring MUM-based features and improvements to our products”. While only at the beginning of MUM’s exploration, Google is convinced that it is “an important milestone towards a future in which Google can understand all the different ways in which people communicate and interpret information in a natural way”.
New developments for the About This Result feature
Speaking of the Search system, there are updates on the About This Result feature, which allows users to better evaluate a result in SERP before clicking on it and reading the content.
It is Prabhakar Raghavan to reveal that as of this month the feature will be applied “to all results in English around the world, with other languages coming” and the goal of providing, “by the end of the year, even more details, such as how a site describes itself, what other sources say about it and related articles to be verified”.

All this answers to the need to provide useful, credible and reliable information, allowing users to “assess the credibility of sources directly in Google Search” and read “details of a website before visiting it, including its description, when it was first indexed and if the connection to the site is secure”.
AI applications in Google Search
The introduction to Google I/O 2021 was obviously entrusted to Sundar Pichai, CEO of Google and Alphabet, who also focused on the applications of systems of a new generation responsible for artificial intelligence, remembering that the company has “made considerable progress in the past 22 years, thanks to our progress in some of the most challenging areas of AI, including translation, images and voice”.

This work has boosted improvements in Google products, “making it possible to talk to someone in another language using the assistant’s interpreter mode, view cherished memories on Photos or use Google Lens to solve a complicated math problem”.
Artificial intelligence has also been applied “to improve the basic research experience for billions of people, making a huge leap forward in a computer’s ability to process natural language”.
However, there are still times when computers “simply do not understand us”, because human language is infinitely complex and “we use it to tell stories, make jokes and share ideas, interweaving concepts that we have learned in the course of our lives”. The richness and flexibility of language make it “one of humanity’s greatest tools and one of the greatest challenges of computer science,” Pichai stresses.
LaMDA, an innovative language model for dialogue applications
In this context, then, comes another important announcement, namely the debut of LaMDA, a language model for dialogue applications that is the last step on the understanding of natural language.
LaMDA stands for Language Model for Dialogue Applications and is open domain, designed to converse on any topic and specially trained on dialogue, to capture many of the nuances that distinguish open conversation from other forms of language thanks to an analysis of the sensibility compared to a given conversation context.

For example, “LaMDA knows the planet Pluto well: so, if a student wanted to find out more about space, he could ask about Pluto and the model would give sensible answers, making learning even more fun and engaging”. If that student “wanted to move on to a different topic, such as how to make a good paper airplane, LaMDA could continue the conversation without any readjustment“.
LaMDA can make information and computing radically more accessible and easier to use, and Google’s goal is to ensure that this technology “meets our incredibly high standards in terms of fairness, accuracy, security and privacy and is developed in a manner consistent with our artificial intelligence principles”. According to Pichai’s anticipations, these conversational features can be incorporated “into products such as Google Assistant, Search and Workspace, but also to provide features to developers and business customers”.
There is one “but”, though: LaMDA is “a huge step forward in natural conversation but is still only trained on text“, while “people communicate with each other through images, text, audio and video”. So it is still necessary to “build multimodal models (Mum) to allow people to ask natural questions about different types of information, a further step towards “more natural and intuitive ways of interacting with Search”.

