
From Google an SEO guide to HTTP status codes, network issues and DNS errors

For some, they risk simply being seemingly meaningless numbers, while someone – more experienced – else, knows that they can hide many pitfalls for the efficiency of the site: by now, however, we should know what the HTTP status codes are and what they mean for our pages, as well as some basic knowledge we have on network errors and DNS problems with the server. For the first time, however, it is Google itself dealing with these issues, with a detailed and official guide on how these situations affect the SEO and performance of the site in Google Search.
Google’s guide on the SEO effects of HTTP status codes and DNS and net issues
The resource is located on the Search Central website, and exacxtly describes “how different HTTP status codes, network errors and DNS errors affect Google Search“.
Specifically, it covers the first 20 status codes that Googlebot has encountered on the Web and the most important network and DNS errors: this means, therefore, that there is no room for more peculiar and bizarre status codes, like the 418 I’m a teapot. In addition, all the problems mentioned on the page generate an error or corresponding alert in the Search Console Crawl Statistics report.
The document is divided into three sections – in fact, HTTP status codes, network errors and DNS errors – offers a descriptive introduction on the topic, with up-to-date information and, above all, interesting details on how Google reacts to various situations. For example:
- Google will try 10 hops for redirects, after which it will consider the URL with a redirect error in the Search Console.
- Redirect 301 vs 302: to Google, a redirect 301 is a strong signal that the redirect target should be canonical, while a redirect 302 is a weak signal that the redirect target should be canonical.
- Status codes 200 ensure that the page goes to the indexing pipeline, but do not guarantee that the page is then effectively indexed.
Google and HTTP status codes
The HTTP status codes, reminds us the document, are generated by the server that hosts the site when it responds to a request made by a client, such as a browser or a crawler. Each HTTP status code has a different meaning, but often the result of the request is the same. For example, there are multiple status codes that signal redirection, but their practical result is the same.
Search Console generates error messages for status codes in the range of 4xx-5xx and for failed redirects (3xx). If the server has responded with a 2xxcode status, the content received in the reply can be considered for indexing (but, as we said, there is no guarantee that it is then actually included in the index).
Status code 2xx (success)
Google considers content for indexing. If the content suggests an error, such as a blank page or an error message, Search Console will display a soft 404 error.
- 200 (success)
- 201 (created)
In both cases, Googlebot moves the content to the indexing pipeline. Indexing systems can index content, but this is not guaranteed.
- 202 (accepted)
Googlebot waits for content for a limited time, then passes everything he received to the indexing pipeline. The timeout depends on the user agent: for example, Googlebot Smartphone may have a different timeout than Googlebot Image.
- 204 (no content)
Googlebot reports to the indexing pipeline that it has not received any content. Search Console may show a soft 404 error in the site index coverage status report.
Status code 3xx (redirects)
Googlebot follows up to 10 redirects, as mentioned: if the crawler does not receive content within 10 hop, Search Console will show a redirect error in the site index coverage report. The number of steps that Googlebot follows depends on the user agent, and for example Googlebot Smartphone might have a different value than Googlebot Image.
Google also reports that in the case of robots.txt follows at least five redirect hops as defined by RFC 1945, then stops and treats it as 404 error to the robots.txt file.
Also, even if the Google Search treats some of these status codes in the same way, you have to consider that they are semantically different: therefore, the advice is to always use the appropriate status code for redirection, so that other clients (e.g., e-reader, other search engines) may benefit.
- 301 (moved permanently)
Googlebot follows the redirection and the indexing pipeline uses the redirection as a strong signal that the redirection target should be canonical.
- 302 (found)
- 303 (see other)
In both cases, Googlebot follows the redirection and the indexing pipeline uses the redirection as a weak signal that the redirection target should be canonical.
- 304 (not modified)
Googlebot reports to the indexing pipeline that the content is the same as the last time it was scanned. The indexing pipeline can recalculate the signals for the URL, but otherwise the status code has no effect on indexing.
- 307 (temporary redirect)
Equivalent to code 302.
- 308 (moved permanently)
Equivalent to code 301.
Status code 4xx (client errors)
Are defined as client errors, those status codes in the 4xx range: in these cases, the indexing pipeline of Google does not consider for indexing the Urls that return this status code, and Urls that are already indexed and return 4xx status code are removed from the index.
More precisely, all 4xx errors, except 429, are treated the same way: Googlebot signals to the indexing pipeline that the content does not exist. The indexing pipeline removes the URL from the index if it has been previously indexed, while the new 404 pages encountered are not processed. The scanning frequency gradually decreases.
Google also invites not to use 401e 403 status codes to limit the crawl rate: other than 429, 4xx status codes “have no effect on the crawl rate“, clarifies the document.
- 400 (bad request)
- 401 (unauthorized)
- 403 (forbidden)
- 404 (not found)
- 410 (gone)
- 411 (length required)
- 429 (too many requests)
Googlebot identifies the 429 status code as a signal that the server is overloaded, considering it a server error.
Status code 5xx (server errors)
Server 429 and 5xx errors cause Google crawlers to temporarily slow the scan; already indexed Urls are stored in the index, but are eventually deleted.
In addition, if the robots.txt file returns a server error status code for more than 30 days, Google will use the last cache copy of the robots.txt; if not available, Google assumes there are no scan restrictions.
- 500 (internal server error)
- 502 (bad gateway)
- 503 (service unavailable)
In all these cases, Googlebot reduces the site’s scan rate: this decrease is proportional to the number of individual Urls that return a server error. Google’s indexing pipeline removes from the index Urls that persistently return a server error.
Google and network and DNS errors
Network and DNS errors have quick and negative effects on the presence of a URL in Google Search.
Googlebot deals with network timeouts, connection recovery, and DNS errors similarly as 5xx server errors. In case of network errors, the scan immediately starts to slow down, since a network error is a sign that the server may not be able to handle the service load. Already indexed Urls that are unreachable will be removed from the Google index within a few days. Search Console can generate errors for each respective error.
Debug of network errors
Network errors occur before Google starts scanning a URL or while scanning the URL. Since they can occur before the server can respond, there is no status code that can suggest problems, and therefore the diagnosis of these errors can be more challenging.
The error may be in any component of the server that handles network traffic. For example, the document says, overloaded network interfaces can drop packs and lead to timeouts (the inability to establish a connection) and reset connections (RST packet sent because a port was closed by mistake).
To debug timeout errors and restore the connection Google suggests to:
- Look at the firewall settings and logs, since there may be a too wide set of blocking rules.
- Look at the network traffic. Use tools like tcpdump and Wireshark you can scan and analyze TCP packets and search for anomalies that point to a specific network component or server module.
- Contact the hosting company if you cannot find anything suspicious.
Debug of DNS errors
Usually, DNS errors depend on an incorrect configuration.
To debug DNS errors, Google invites you to:
- Check the DNS records, to verify that the A and CNAME records are addressed to the correct IP addresses and hostnames, as shown in the image.

- Verify that all name servers point toward the correct IP addresses of the site, as shown in the image.
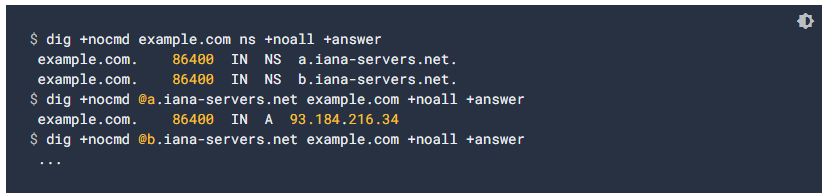
- Wait for the changes to propagate: if we have made changes to the DNS configuration in the last 72 hours, you may have to wait for the changes to spread across the global DNS network. To accelerate propagation, we can empty the cache of Google’s public DNS.
- Check the DNS server: if we run our private DNS server, we need to make sure it is intact and not overloaded.
