
A guide to query strings URL parameters for the SEO

Query strings and URL parameters are very common elements in the address structure of websites; typically, they are believed to be loved by developers and those who study the data of analytics tools, while instead they create more problems on the user experience side, because infinite combinations can create thousands of URL variants from the same content.
In fact, we talk about central aspects in the wider discourse about the URLs of a site and how to manage these aspects effectively for SEO, which can create some difficulty if not treated properly, but that play an important role in the management of the site: in short, let’s find out what are the URL parameters and query strings, because they are useful and what are the precautions to be taken to use them in an SEO-friendly way.
What are the URL parameters
Also known as URL variables or query strings, parameters are the part of a URL that contains the data to be input to a program, which cannot fit into a hierarchical structure of paths and which are generated based on user requests.
From a technical point of view, they are the portion of the address following to the right the base URL and the question mark ? (which is the last element excluded from the query string) and includes two fields, the parameter itself and its value.
Compared to the URL format, and given the variable nature of the strings, the syntax of the parameter is not defined in a formal, unique and precise, but follows a scheme adopted by all browsers and scripting languages, with the character = (equal) which introduces the value and the character & that performs the function of concatenating different parameters in the same address.
Examples of most common query strings
These address variables are added to basic URLs and lead to a custom view of the page; they are generated for example when you fill out a filled out form or, in a very common way, when we apply a filter to a list of products on an eCommerce.
Among the most used parameters on sites there are those that are useful to:
- Track visits. They do not modify the content displayed by the user but serve precisely to monitor and track visits and click information in web analytics platforms (as a result of content sharing on social networks, via email or PPC campaigns). The basic advice is to exclude indexing of these parameterized URLs from search engines and not to include the canonical on these addresses.
- Sort. Perhaps the most well-known usage, which serves to organize the sorting of the results of a list, as in the case of the price filter. As in the previous case, it would be convenient not to index the pages with this parameter, which in practice contains the same elements as the not parameterized URLs, and exclude them from the canonical rel tag.
- Filter. They serve to circumscribe the results on the basis of a characteristic, such as the color of a product, the brand or the year of publication of the articles. They are a very important string on which it is necessary to reason, monitoring its effects: if it gives rise to useful and searched contents it may be advisable to allow the indexing of the generated pages and also the canonicalization. In this case, you will also need to optimize title, meta description and onpage content. On the contrary, if from the filter are born pages that offer only duplicate content and without real added value in terms of searches it is advisable not to index and not to provide canonical.
- Identification. With query strings you can specify precisely the items to be displayed, such as articles, categories, user profiles or product sheets: you usually have these URLs indexed because they uniquely define an element, also taking care of the optimization of the contents thus generated (title tag and meta description first of all). However, if there are alternative friendly URLs you can consider the option not to index the parameterized pages.
- Pagination. URL parameters can be used to number pages and manage the pagination of an archive; in order not to miss the relevant pages, these URLs must be left free and open for crawlers.
- Translation. Another frequent case is the use of query strings for multilingual versions of sites (alternative to gtld methods with a system of URL folders or cctld dedicated), which then generates alternative pages with translation of the content in another language.
- Search. These are the URLs that are generated by queries typed through the “search” command of the site.
How to manage URL parameters in a SEO friendly way
As you can see from the previous mirror, the first problem for SEO that comes from the use of URL parameters is that of duplicate content, which occurs when query strings do not make significant changes to the content of a page. For example, a URL with a tracking tag or a session ID is identical to the original.
First risk, the cannibalization of keywords
Clearly, this criticality is worrying for large sites that repeat the use of parameters for various types of filters and functions, which is why it is essential to properly manage the indexing and canonicalization of the generated resources. Otherwise, you can easily face the cannibalization of keywords and a worsening of Google’s assessments of the overall quality of the site, because the new URLs do not add any real value to the user.
Waste of crawl budget
From a technical point of view, then, scanning pages of redundant parameters makes you consume crawl budget towards non-strategic resources, thus reducing the ability of the site to submit relevant pages to crawlers such as Googlebot and increasing server load at the same time.
In addition, identical or similar variations of the same page content may make different versions of social links and shares available: the crawler, in this case, may have uncertainties about the proofread pages to be indexed for the search query and the pagerank of the page is unproductively diluted.
Less user-friendly address
As we said in a previous deepening, the URL also has a value for the user experience and among the best SEO practices is recommended to use short and simple addresses: the URL parameters instead create long strings, difficult to read and, often, seemingly suspicious and less convincing for a click from email, social media and so on. Features that can negatively affect the site’s CTR and page performance and that, in the long run, can help reduce brand engagement.
URL parameters, tips to SEO friendly manage query strings
We have therefore seen what are the query strings and what risks entails their management not effective on the sites, and then it’s time to find out what are the best practices for not having problems. There are (at least) six ways to try to improve URL parameters and make them more SEO friendly, thus continuing to take advantage of the benefits of filters and strings smoothly for usability, crawl budget and SEO optimization.
Delete the unnecessary URL parameters
Limiting unnecessary URL parameters: The easiest path is to identify how and why parameters are generated and understand which ones offer value to users and site and which ones, instead, turn out to be useless if not harmful to SEO.
We can therefore eliminate unnecessary query strings (filters rarely used by users, parameters that do not perform useful functions, tracking that can be made easier by cookies), avoid that empty values are realized, Be careful not to apply multiple parameters with same name and different value, take care of sorting these elements.
Using the rel canonical to give a hyerarchy to pages
On the use of the canonical rel we have already dwelled, and therefore we can only add that this intervention has the advantages (such as the simplicity of implementation, the high guarantee of avoiding problems of duplication of content and the possibility of consolidating the ranking signals on the preferred URL), but also the negative aspects. Even with the canonical, in fact, you can waste the crawl budget on parameter pages, and sometimes Google may not use the indication (we were talking about it some time ago); moreover, it is not applicable to all kinds of parameters.
Setting Noindex directives in Meta Robots
The third type of intervention concerns meta robots and the possibility of blocking the indexing of the search with a “noindex” tag, which as we know is the method recommended by Google for this goal, which has officially retired the noindex in the robots.txt file! ).
We can thus set a noindex directive for each page based on parameters that does not add SEO value, thus avoiding that it can be inserted in the index of the search engine; moreover, there is also the probability that URLs with a “noindex” tag are scanned less frequently and, in the long term, Google may independently decide to put in nofollow the links of the page.
The advantage of this solution lies in its simplicity and its effectiveness in preventing the duplication of content; moreover, it is applicable to all types of URL parameters that we want to exclude from the Index and also allows you to remove pages already indexed by Google. At the same time, however, the Noindex directive in Meta Robots is seen by the search engine as a strong hint, but not an obligation and does not prevent Googlebot and other crawlers from scanning pages, only ensuring that they do so less frequently; obviously, then, you do not consolidate the ranking signals provided by the site.
Using the Disallow in the Robots.txt file
Another possible way is to use the Disallow directive in the robots.txt file, which is the first element that search engines look for on the site before scanning: finding this specification, they keep away from the pages. This way you can block access to crawlers to any page with URL parameter or specify individually the query strings that we do not want to index.
Also in this case we talk about a simple technical implementation, with immediate positive effects and suitable for every type of parameter: with the disallow a more efficient management of the crawl budget is generated and duplicate contents are avoided. The negative points are instead the impossibility to consolidate signals for the positioning and, above all, to remove the existing URLs from the Index.
Use the URL Parameters tool in Google Search Console
Within the Google webmaster tools there is a function that allows you to manage these elements: it is simply called “URL Parameters tool” and is dedicated to sites that use “URL parameters for non-significant page variants (e.g., color=red and color=green) or parameters that allow you to basically show the same content but with different URLs (e.g., example.com/shirts?style=polo,long-sleeve and example.com/shirts?style=polo&style=long-sleeve)”, as read in the guide to avoid “an inefficient site scan”.
It is important to learn more about how to use this tool better, because it is the same page written by the Google team to highlight a warning message: incorrect use could cause damage to the site and its placement in Google Search, because the search engine “may ignore important pages of your site without notifying you or reporting ignored pages. If it seems a little drastic it is because many people use the tool incorrectly or without having an actual need. If you have doubts about the correct use of the tool, it would be better not to use it“.
What the Google URL Parameters tool is for
The tool prevents Google from scanning URLs that contain specific parameters or parameters with specific values and, as in other cases, serves to prevent the crawler from scanning duplicate pages. Its effects are very direct: the “behavior of the parameters applies to the entire property” and it is not “possible to limit the scanning behavior of a certain parameter to a specific URL or part of your site”.
When to use the Search Console tool, the requirements
According to Google, there are two situations that should push you to use the URL Parameters tool: a site with over a thousand pages and (simultaneously) a large number in the logs of duplicate pages indexed by Googlebot where only the URL parameters are different (for example example example example.com?product=green_dress and example.com?type=dress&color=green).
How to use the tool
The key question to address this is “how does the parameter affect the content of the page?” the best way to manage the settings and thus optimize the performance of the SEO side pages.
As default for the parameters already known there is the possibility to let Googlebot decide how to manage the parameters: the crawler analyzes the site and determines what is the best and most effective way. For those who want to control the operations, you can decide to never block URLs with a specific parameter, to scan only URLs with certain values, to block the scan for specific parameters.
In general, among the pros of this tool we can report for sure its usability, which does not take any time to developers (and, entrusting the tasks to Googlebot, even those who manage the site); moreover, is suitable for any type of URL parameter, can prevent the duplication of content and allows a more efficient use of the scanning budget. There are also some cons, however: first, like other interventions it does not consolidate the signals for positioning and is not a mandatory directive, but mostly it only works for Googlebot and therefore doesn’t communicate the same messages to other alternative search engine crawlers, like Bing.
Choose only static URLs
The last solution is very drastic and time-consuming: it involves converting all URL parameters to static URLs by rewriting server-side addresses and using the redirect 301. On the other hand, according to many the best way to manage query strings is to avoid them altogether, also because subfolders help Google to understand the structure of the site and static URLs based on keywords have been a milestone of on page SEO.
An approach with advantages and limitations
This approach works well with descriptive parameters based on keywords, such as those that identify categories, products or filters for attributes relevant to search engines, and is also effective for translated content. However, it becomes problematic for items where keywords are not relevant, such as price, where having a filter such as a static and indexable URL does not offer any SEO value. In addition, it is also difficult for search parameters, since each query generated by the user would create a static page that can degenerate into cannibalization compared to the canonical, or still submit to crawlers pages of low quality content whenever a user searches for an article that is not present.
This does not work much even with tracking (Google Analytics will not recognize a static version of the UTM parameter), and especially replace dynamic parameters with static URLs for things like pagination, onsite search box results or sorting do not resolve duplicate content, crawl budget or dilution of link juice.
Getting to the point, for many websites it is neither possible nor advisable to completely delete parameters if the goal is to provide an optimal user experience, nor would it be the best SEO practice. Thus, a compromise could be to implement query strings for parameters that should not be indexed in Google Search, and instead use static URLs for the most relevant parameters.
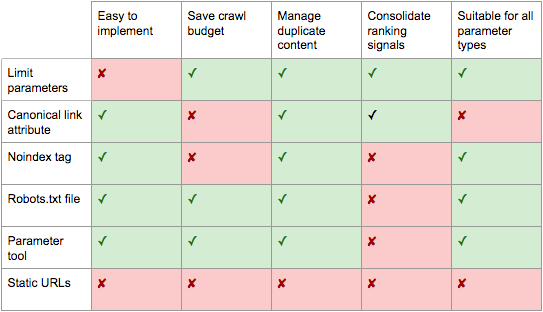
There is not a single perfect solution to manage URL parameters
From what we wrote it should be clear that there is no perfect solution to manage URL parameters effectively for the user experience and for SEO, because it all depends on the evaluations related to the site: in some cases it may be more important to optimize the crawl budget than the consolidation of ranking signals, while in others the priorities are opposite.
SEO optimization of query strings, the path
In principle, a standard path of SEO-friendly optimization of query strings could be the following, proposed by Jes Scholz on Search Engine Journal (from which we also drew the final image on the pros and cons of all the solutions described):
- Launch a keyword research to understand what parameters should be static URLs and potentially placeable on search engines.
- Implement proper pagination management with Rel=prev/next.
- For all other URLs with parameters, implement consistent sorting rules, which use keys only once and prevent empty values to limit the number of URLs.
- Add a canonical to the pages of parameters that may have classification possibilities.
- Configure URL parameter management in both Google and Bing as a safeguard to help search engines understand the function of each parameter.
- Check that URLs based on parameters are not sent to the Sitemap.
